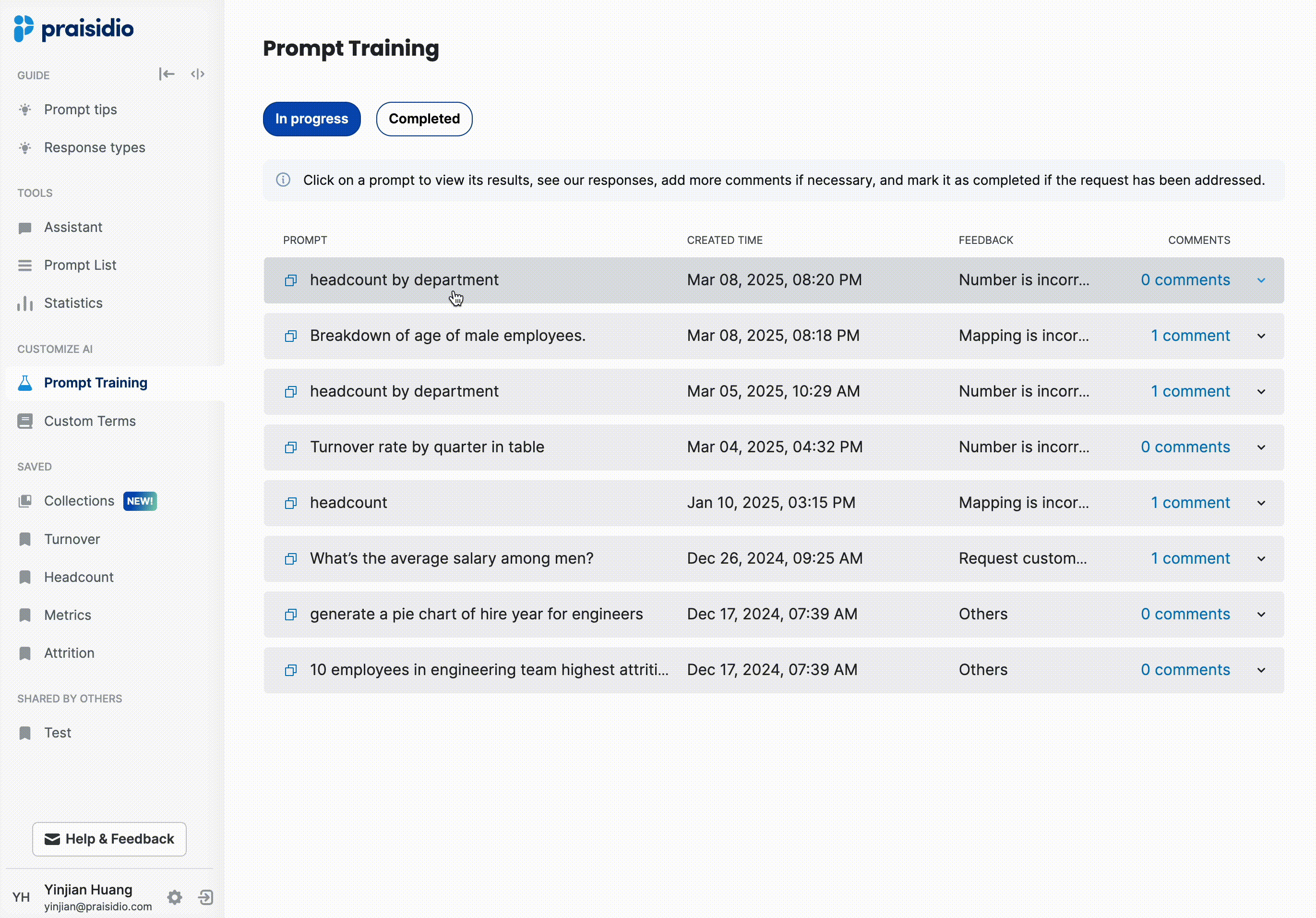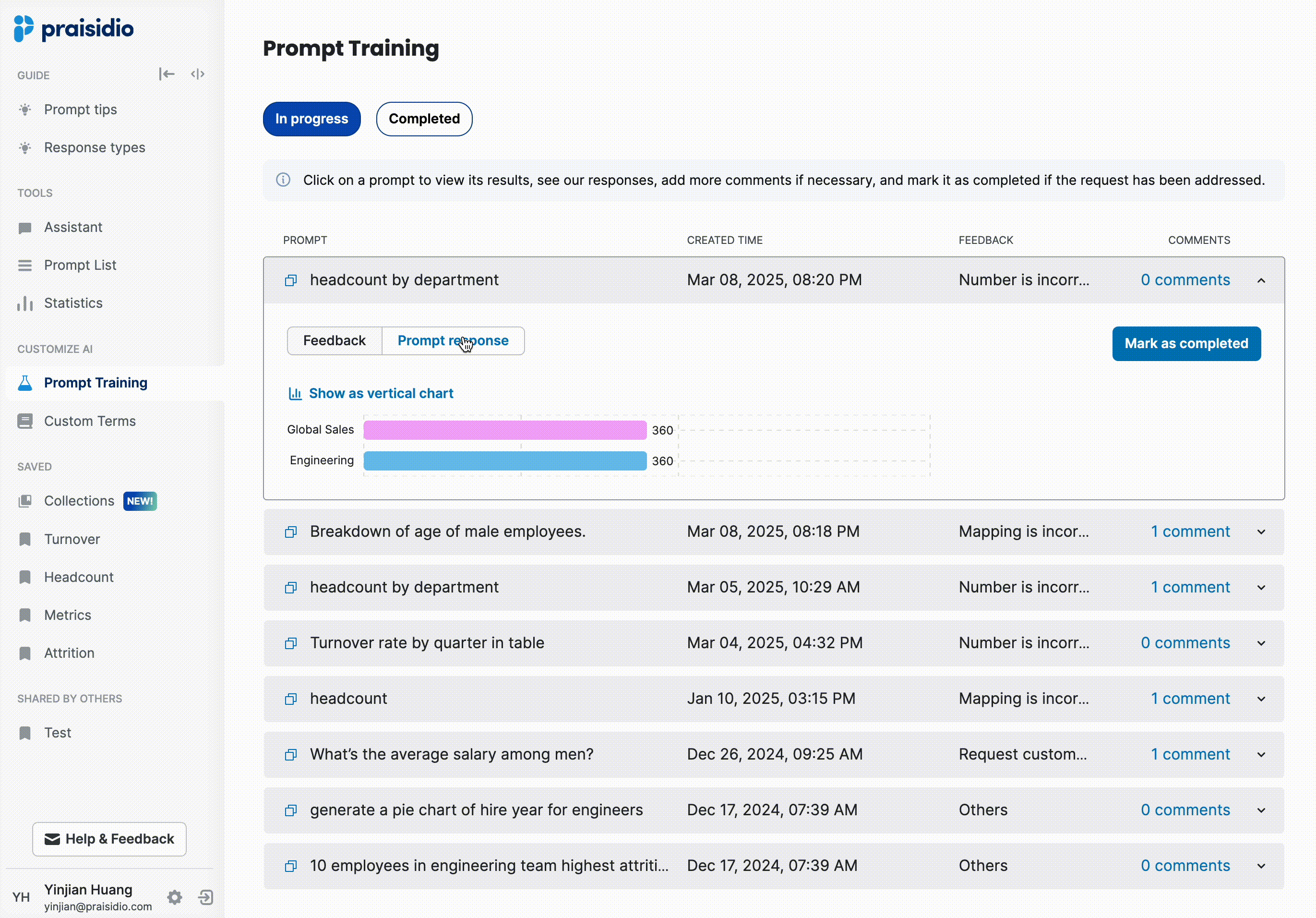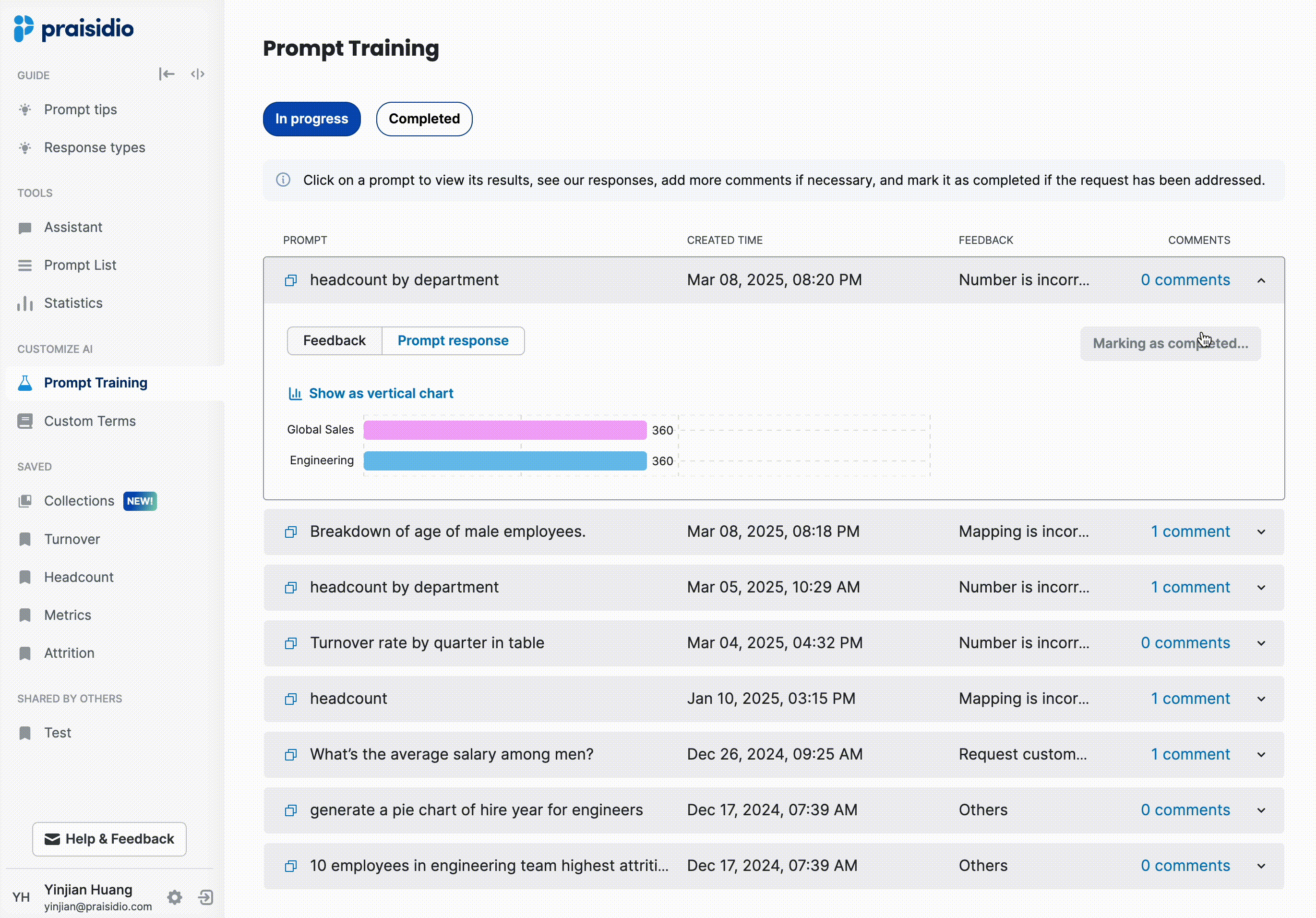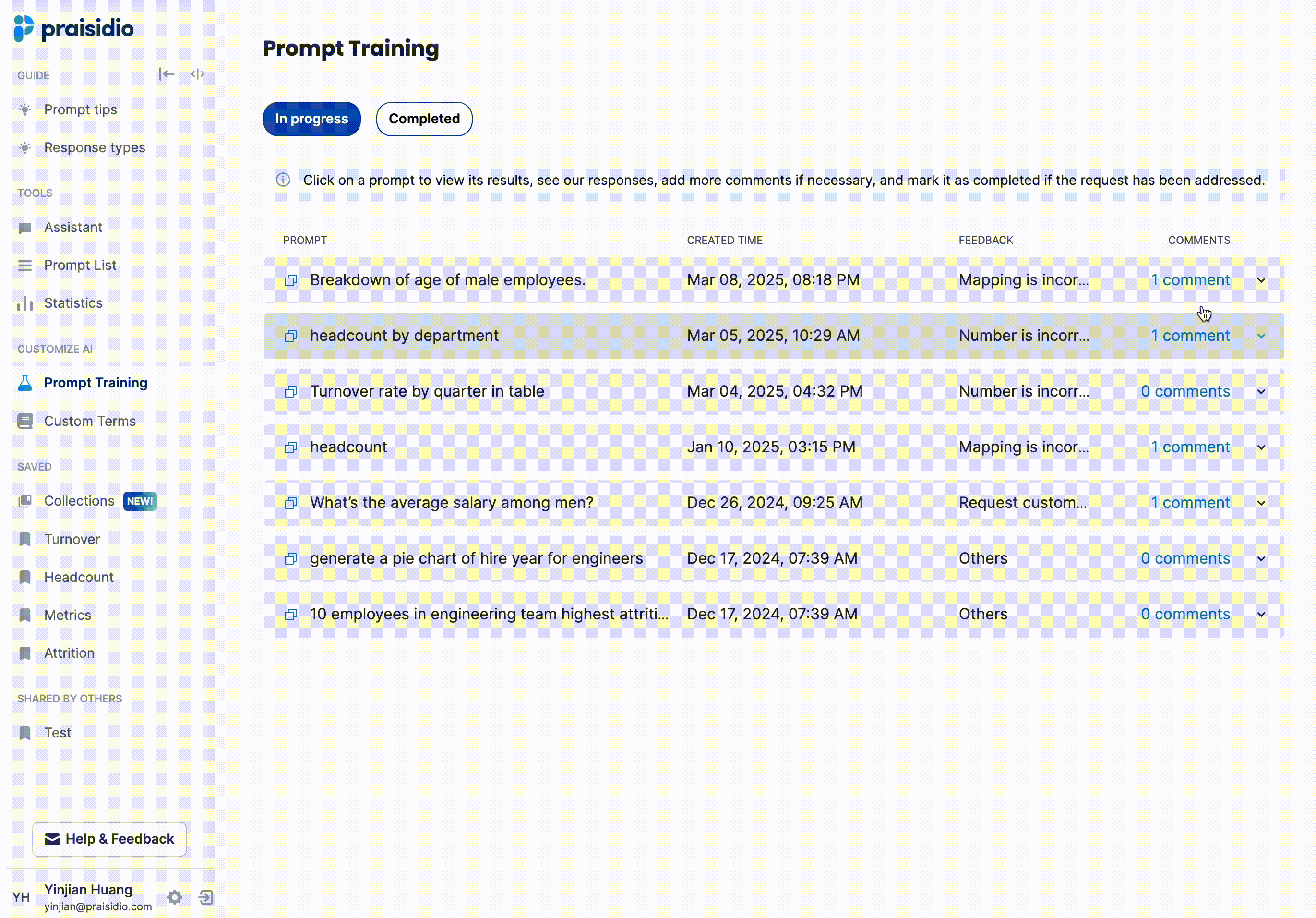
Phase 1: Increasing Activation from 10% → 30% with AI Transparency
Problem: Users didn’t trust AI calculations → They stopped using it
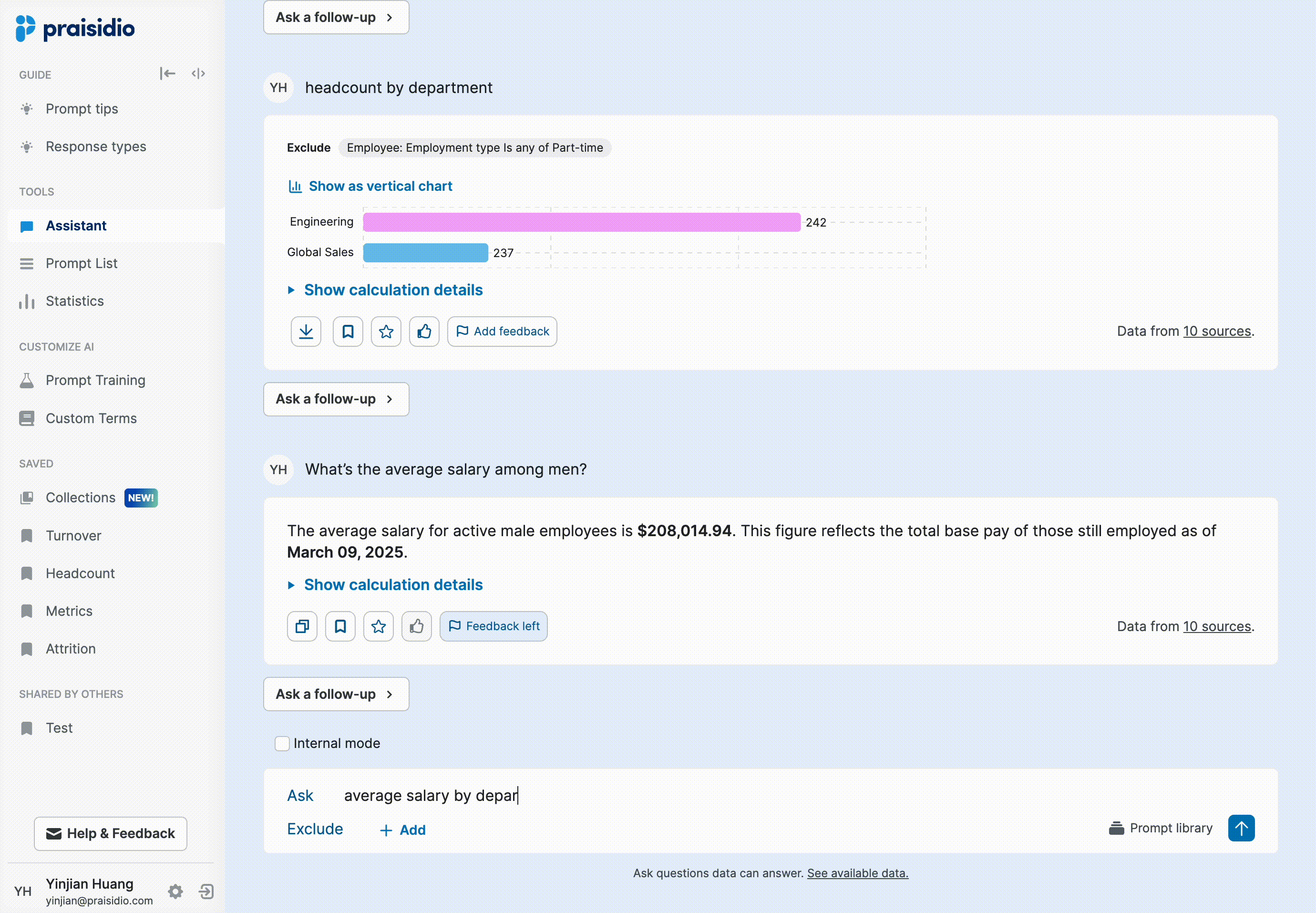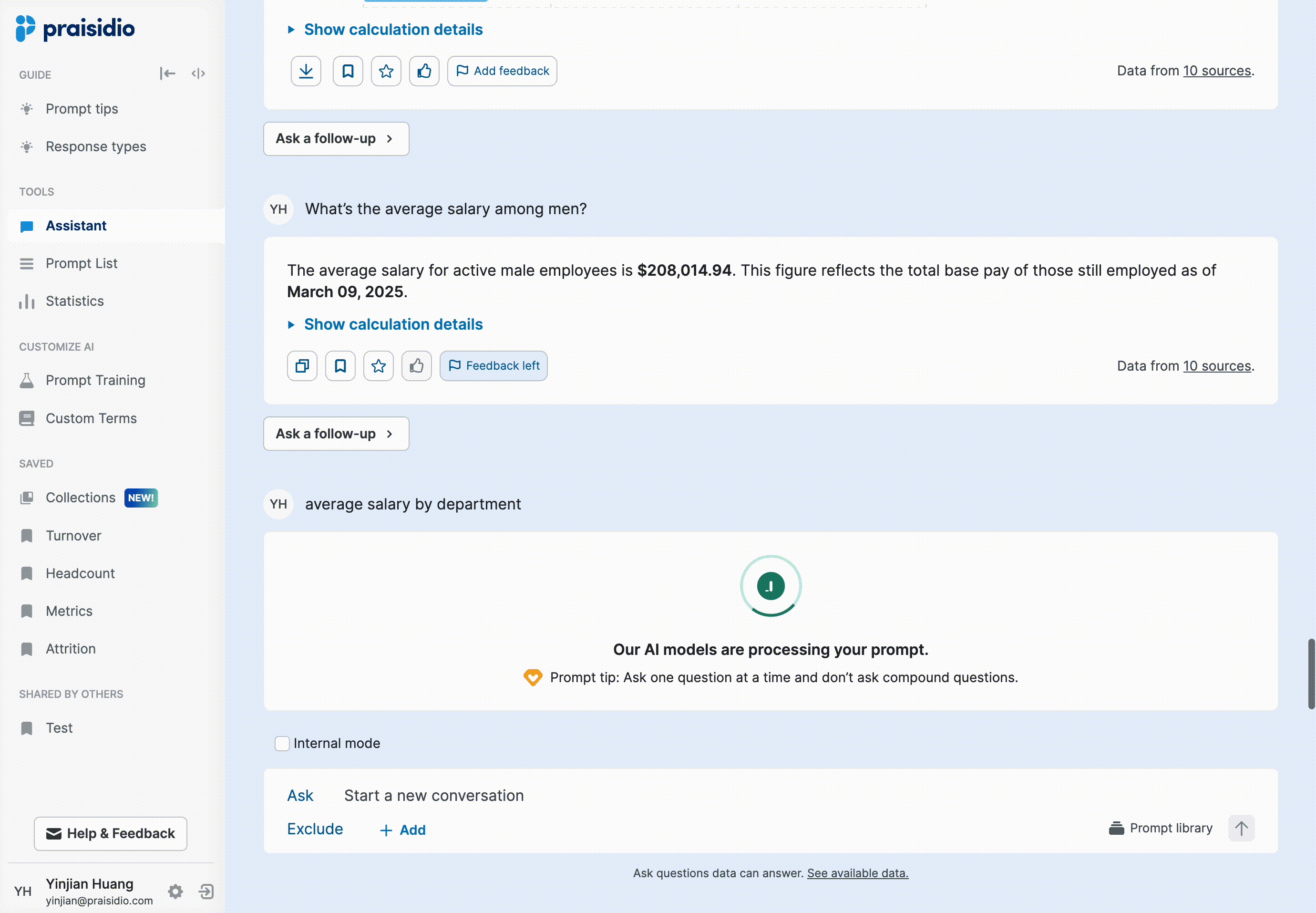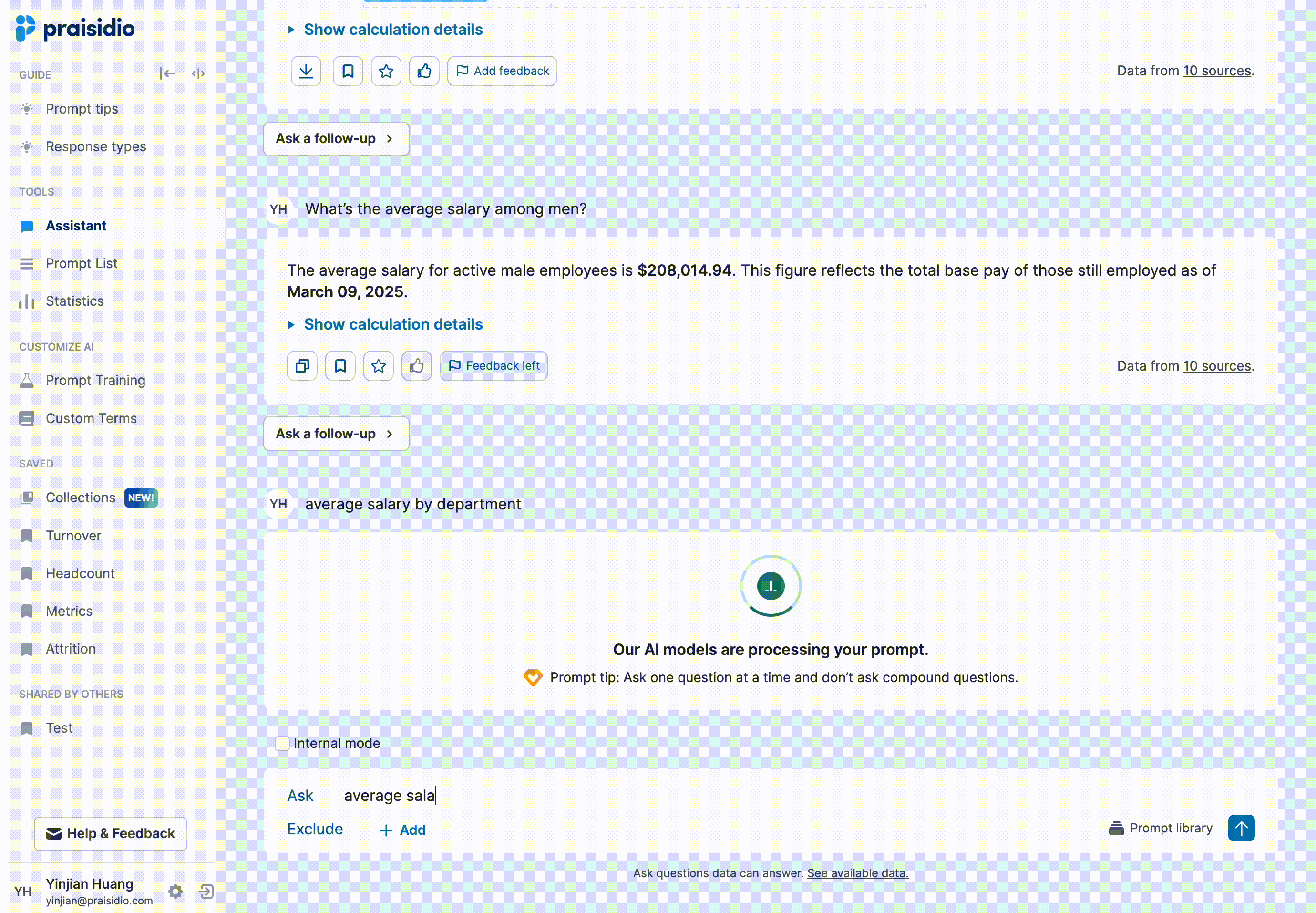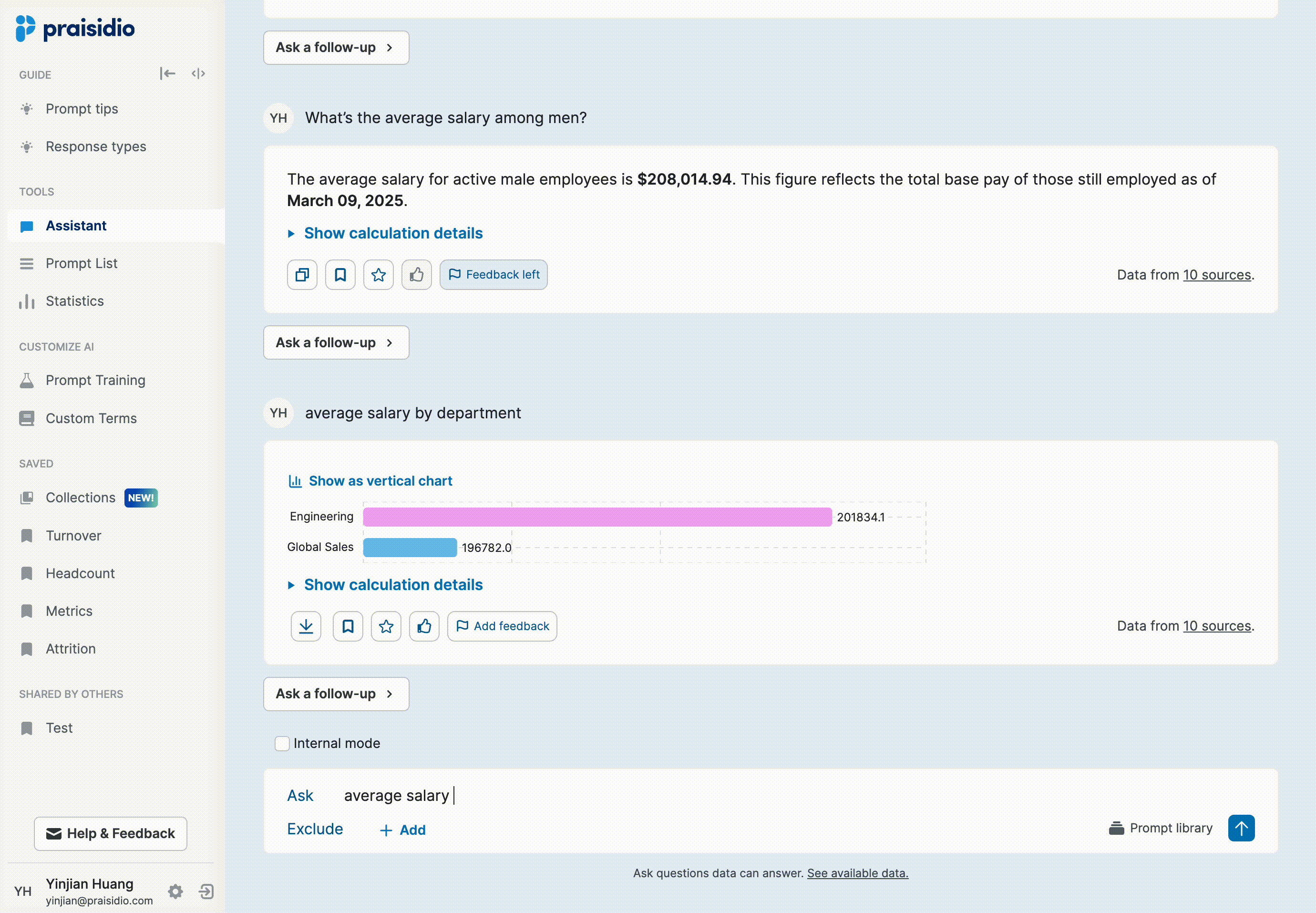
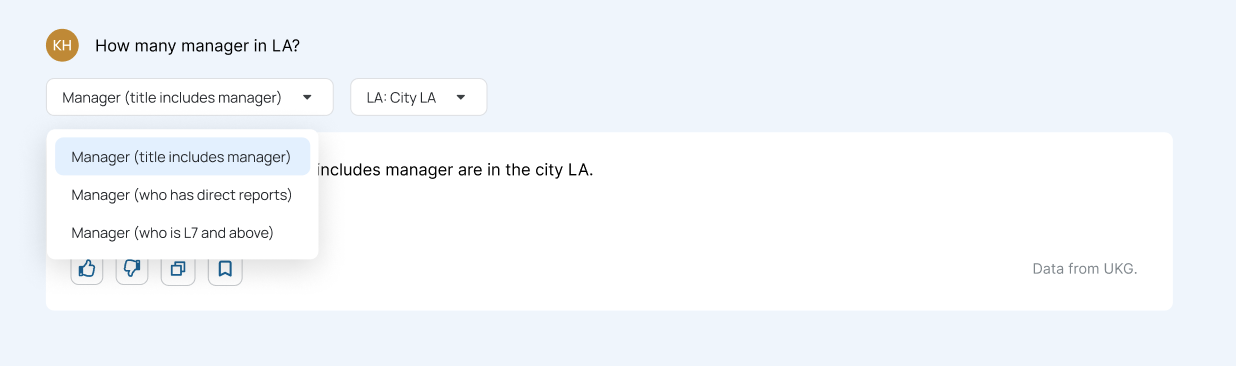
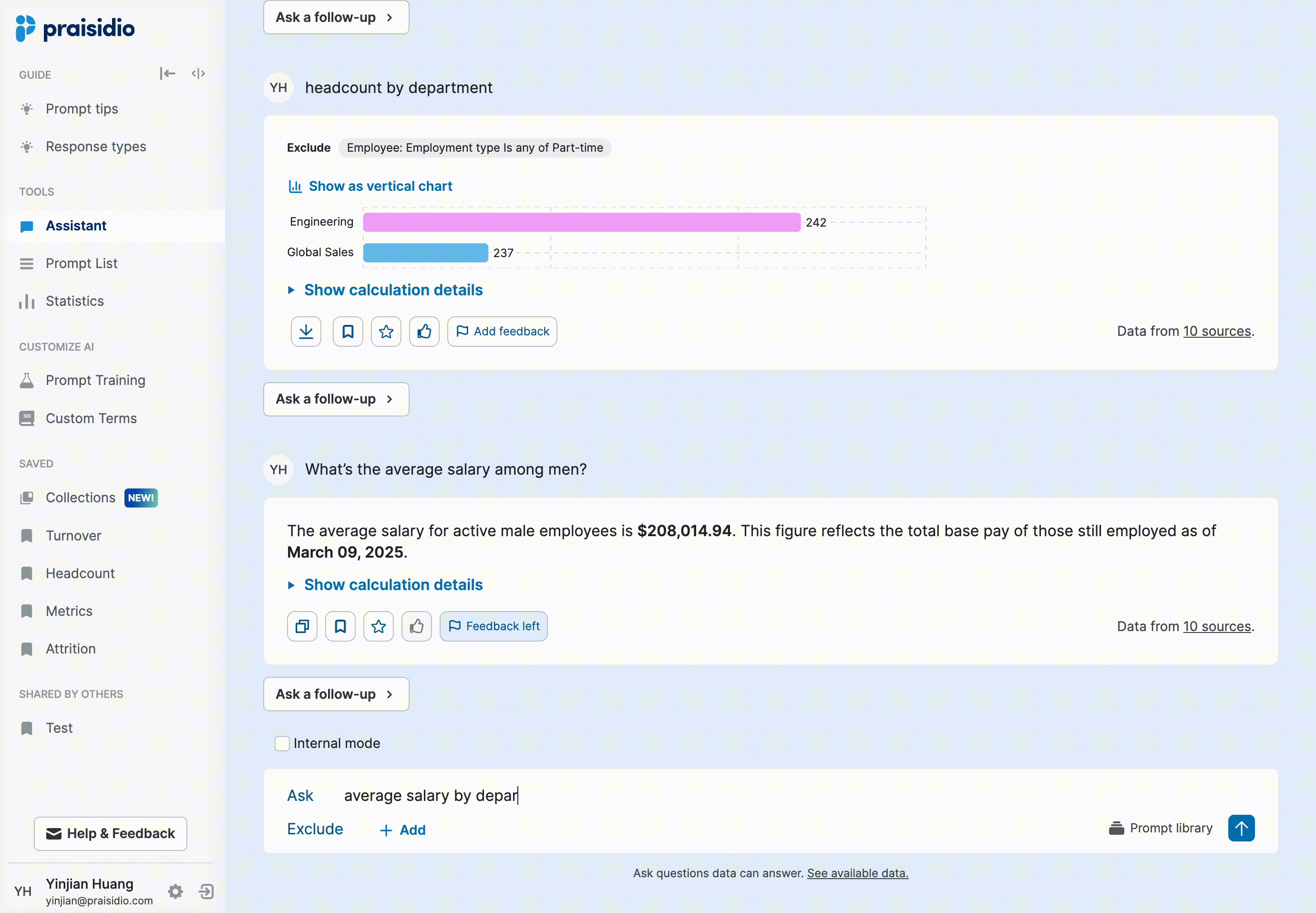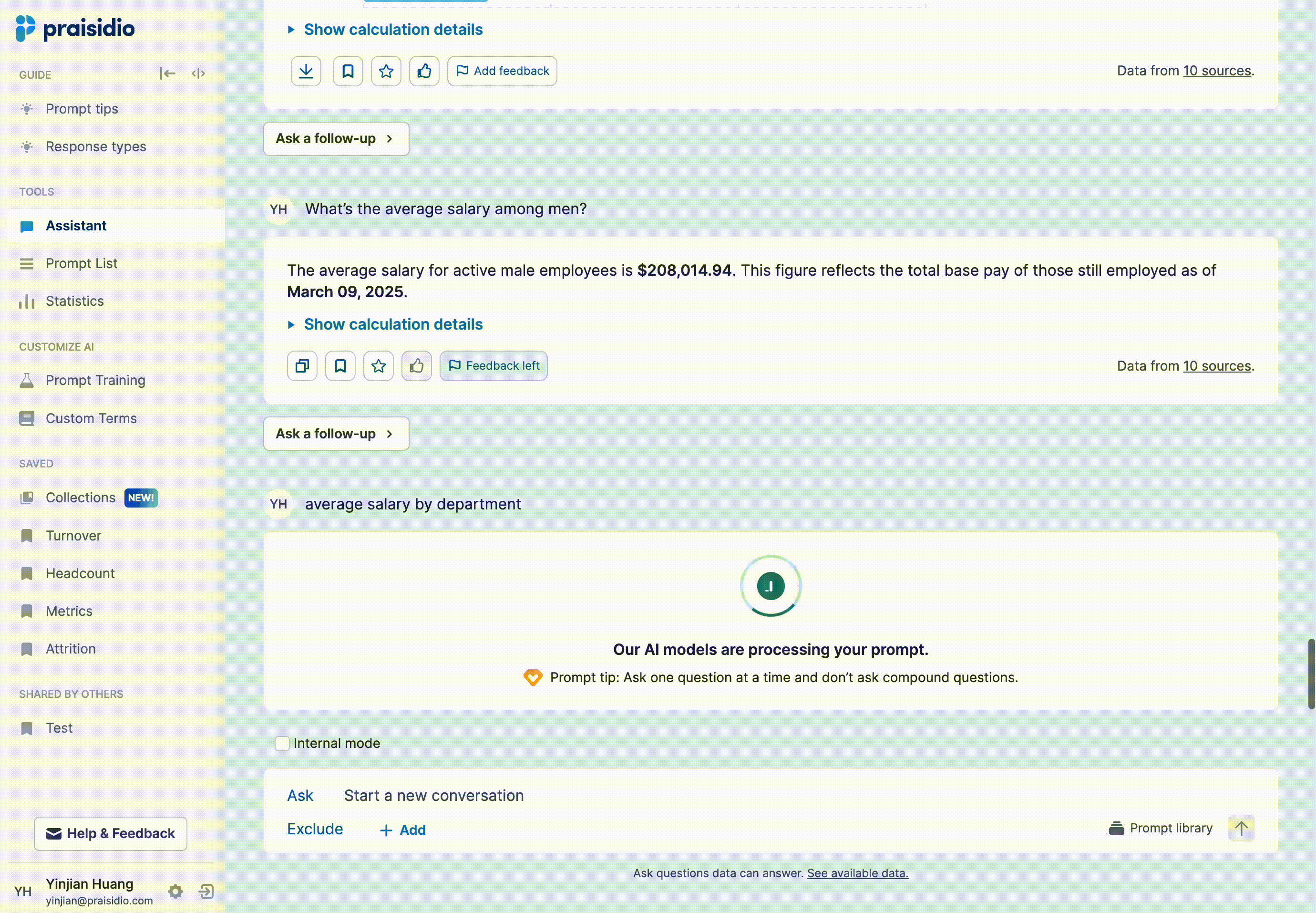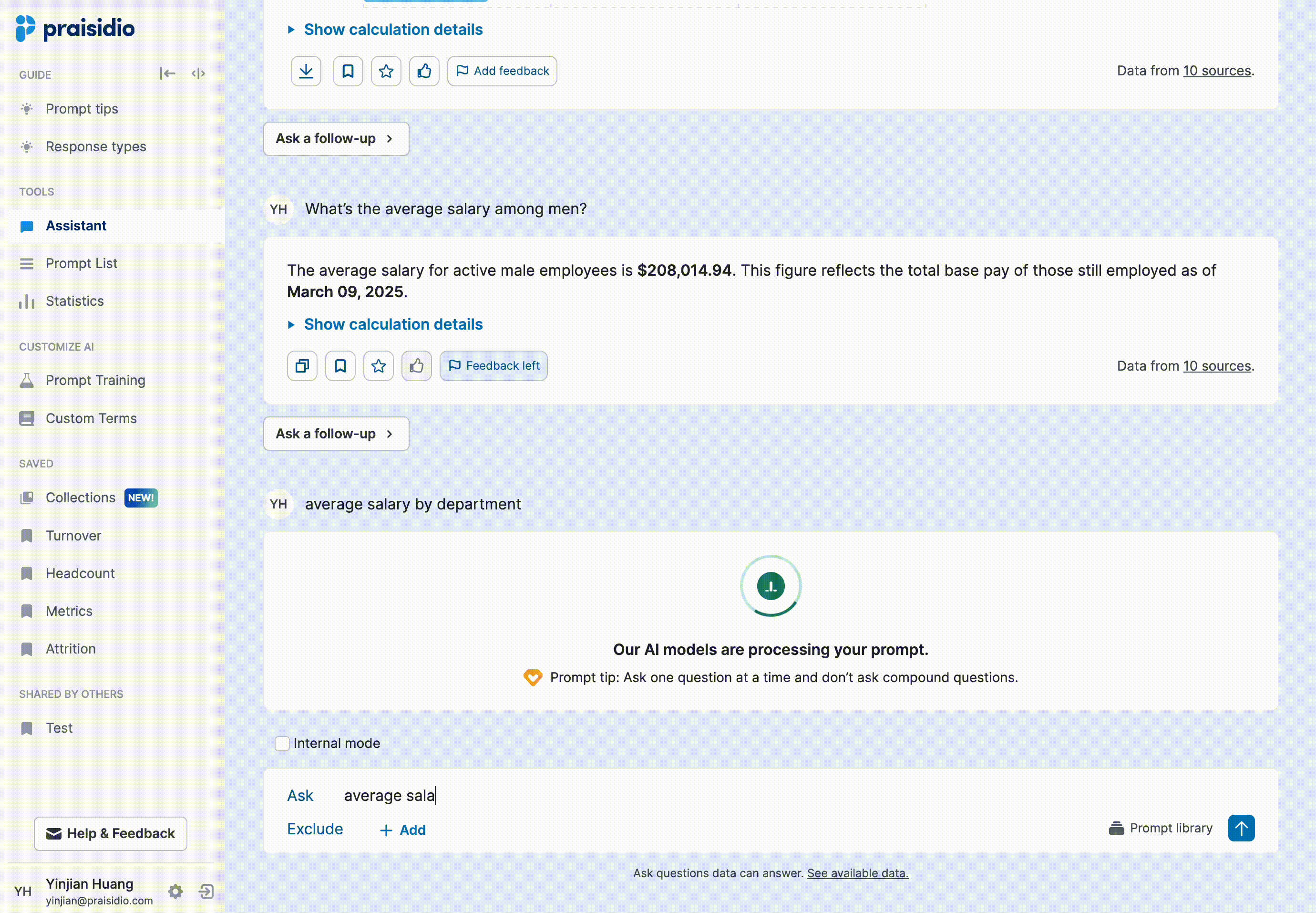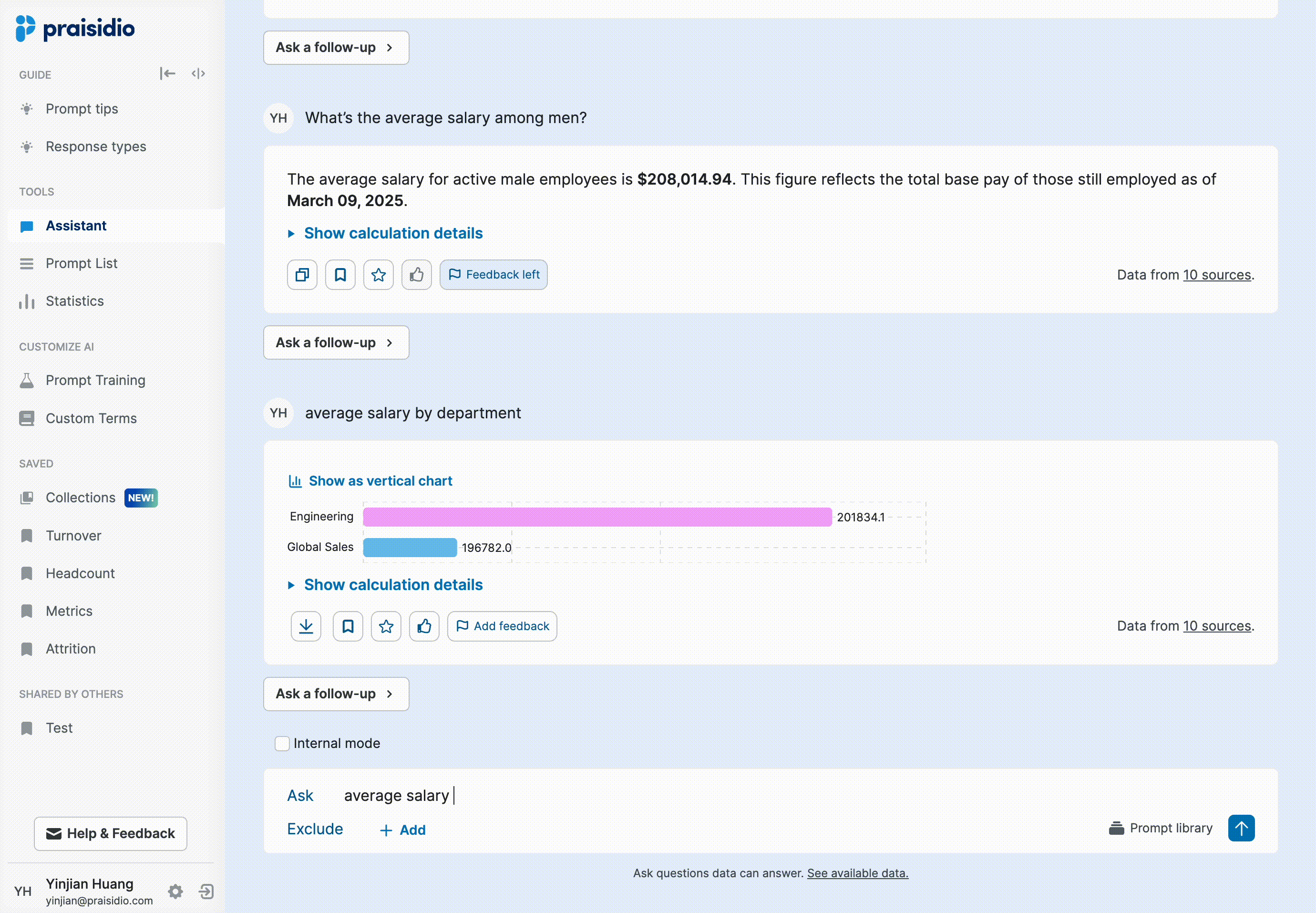
Users would ask a few workforce-related questions, but when they saw AI-generated numbers, they couldn’t verify if they were correct. If the response seemed “off,” they lost confidence and didn’t return.
Initial attempt: adding more context in responses made it too long
To improve trust, I collaborated with the model engineer to add more contextual details directly in the AI response, such as time range, applied filters, and field mappings. However, this made responses long, and users still wanted even more detailed explanations around how numbers were calculated.
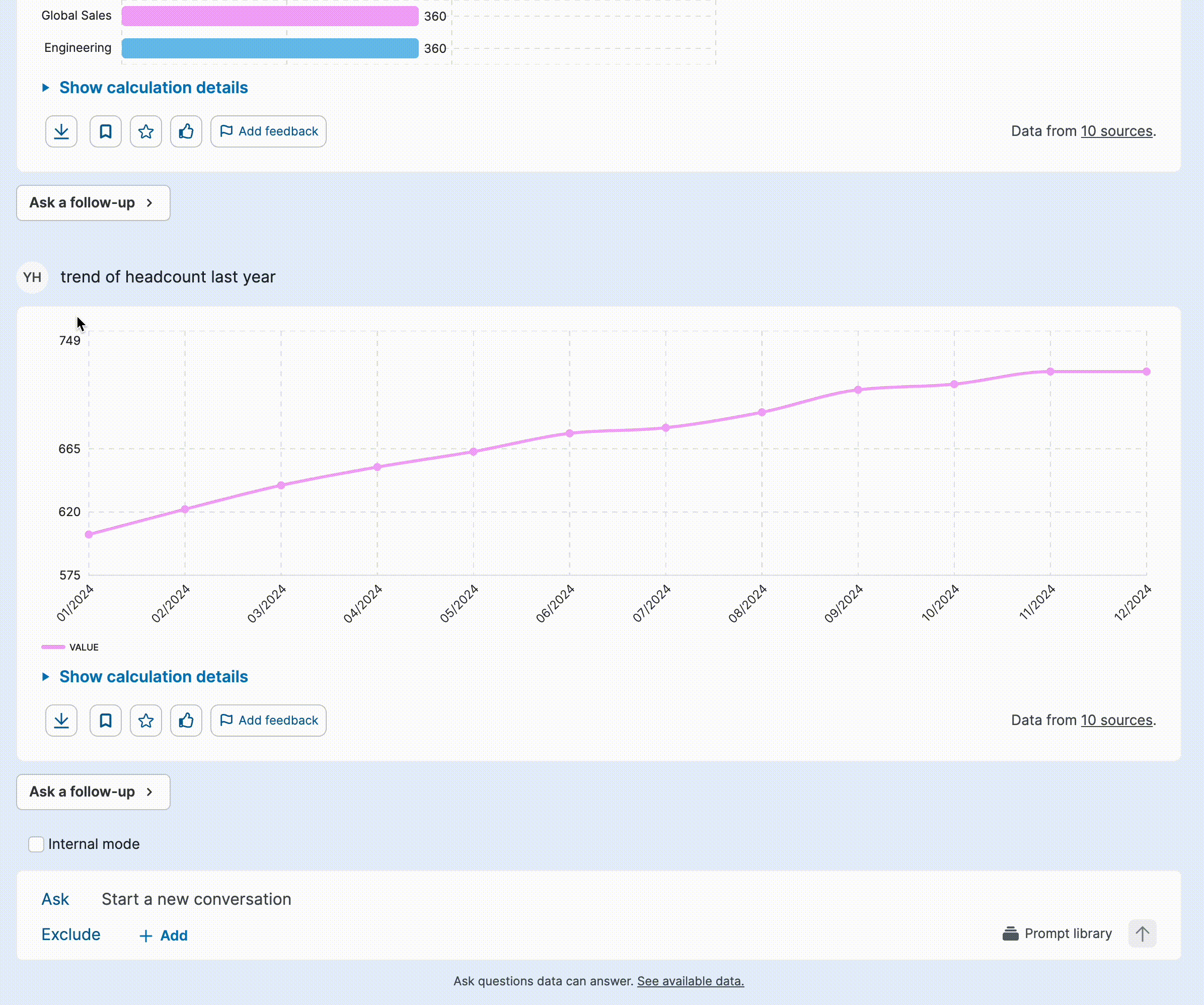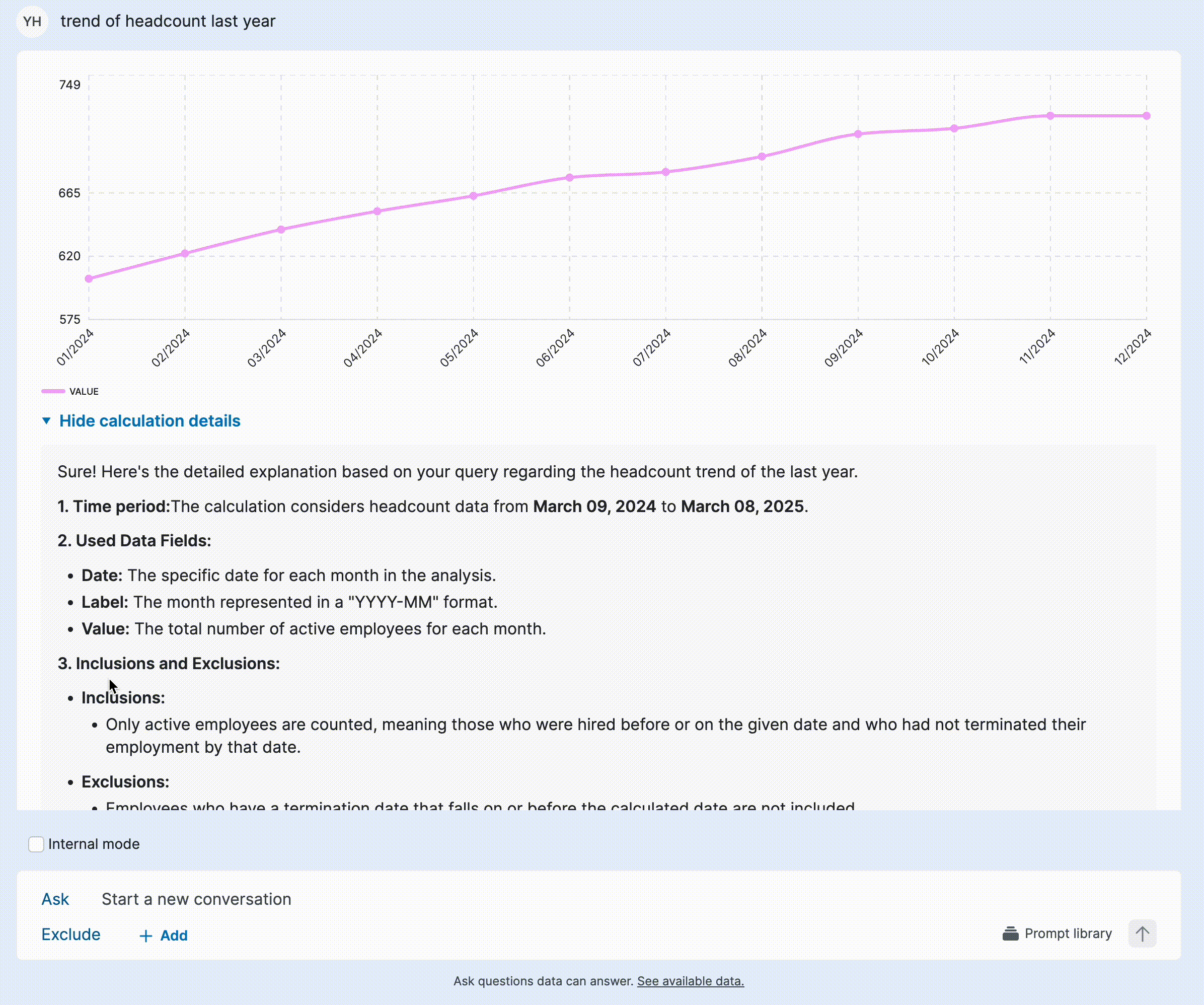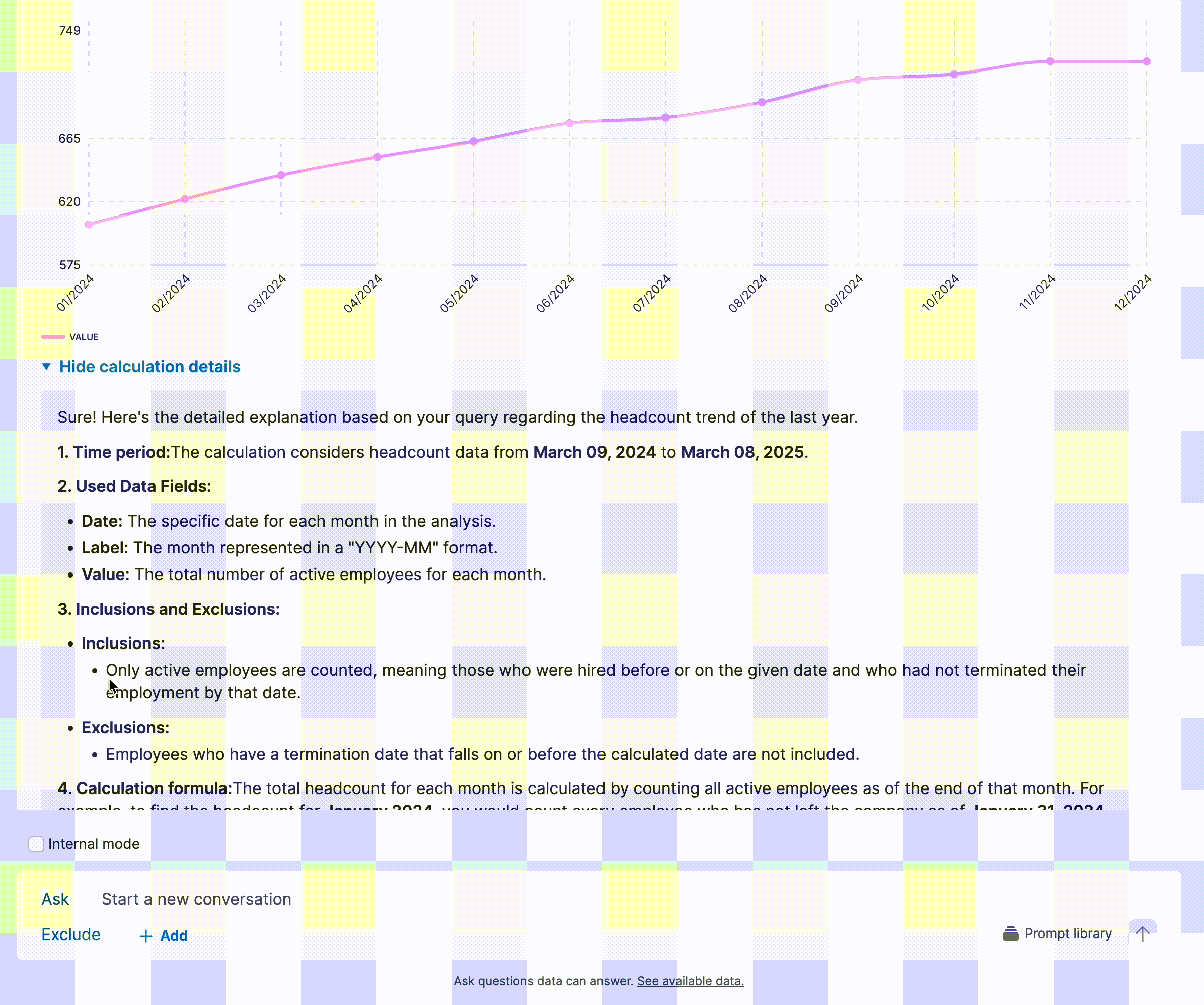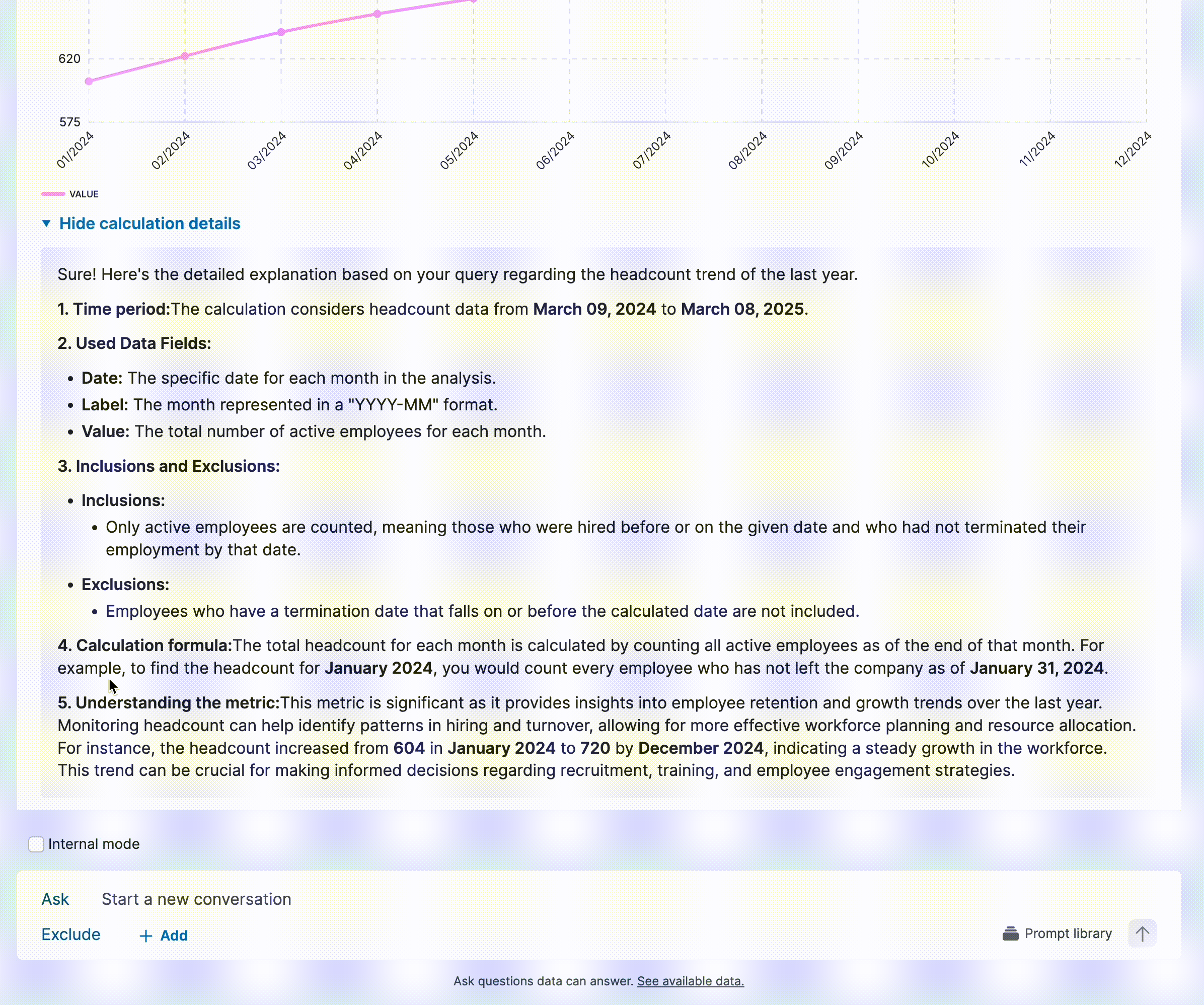
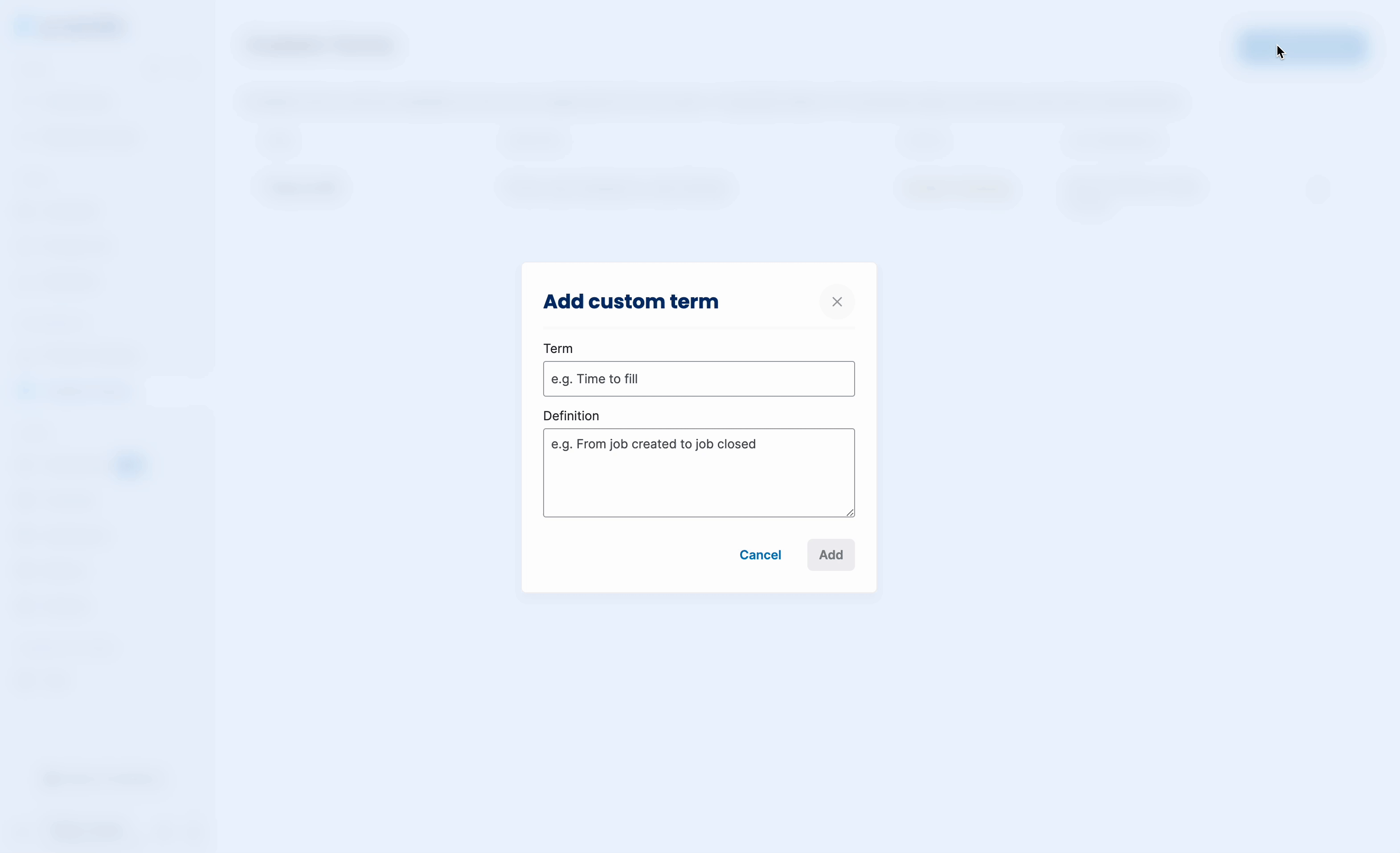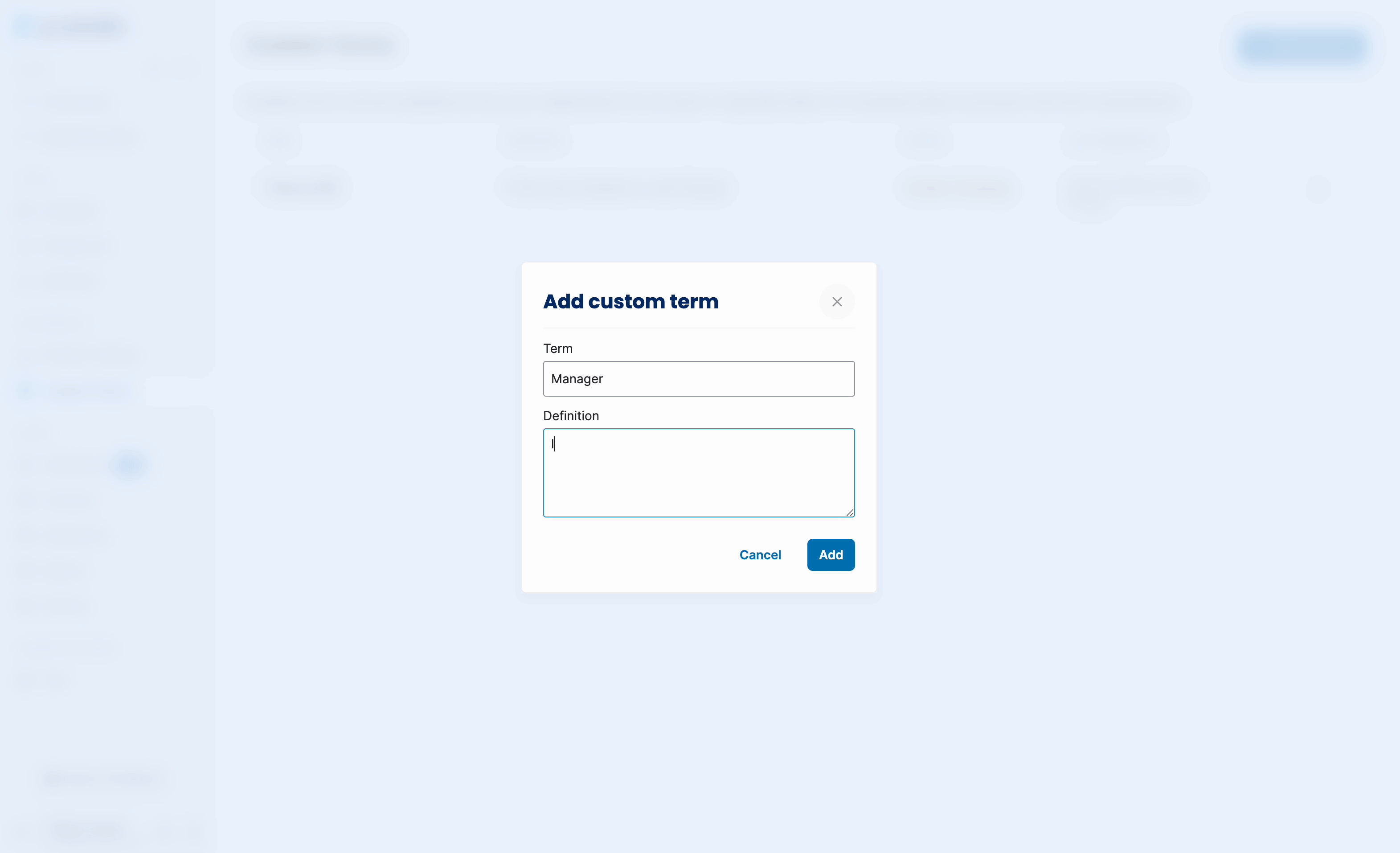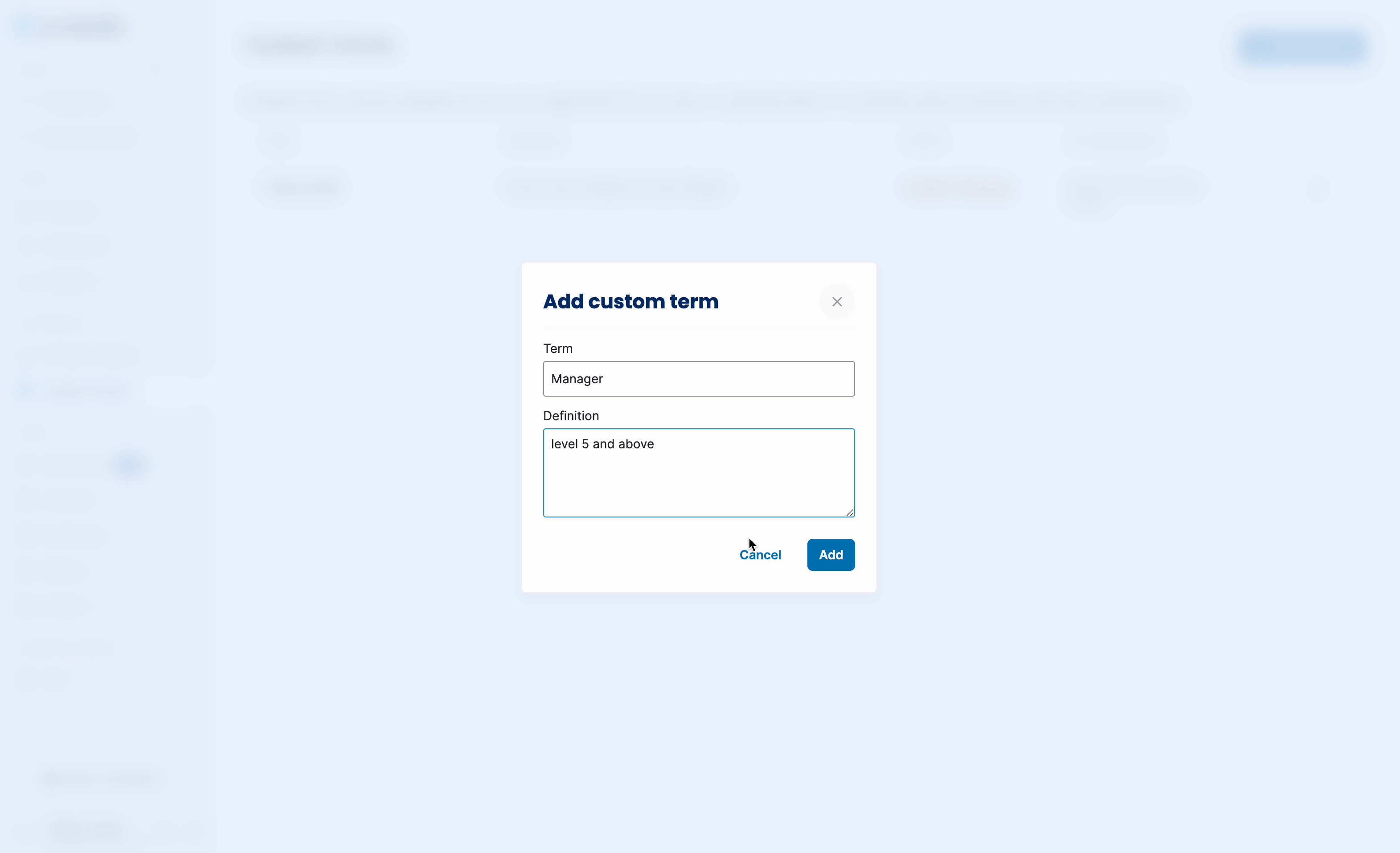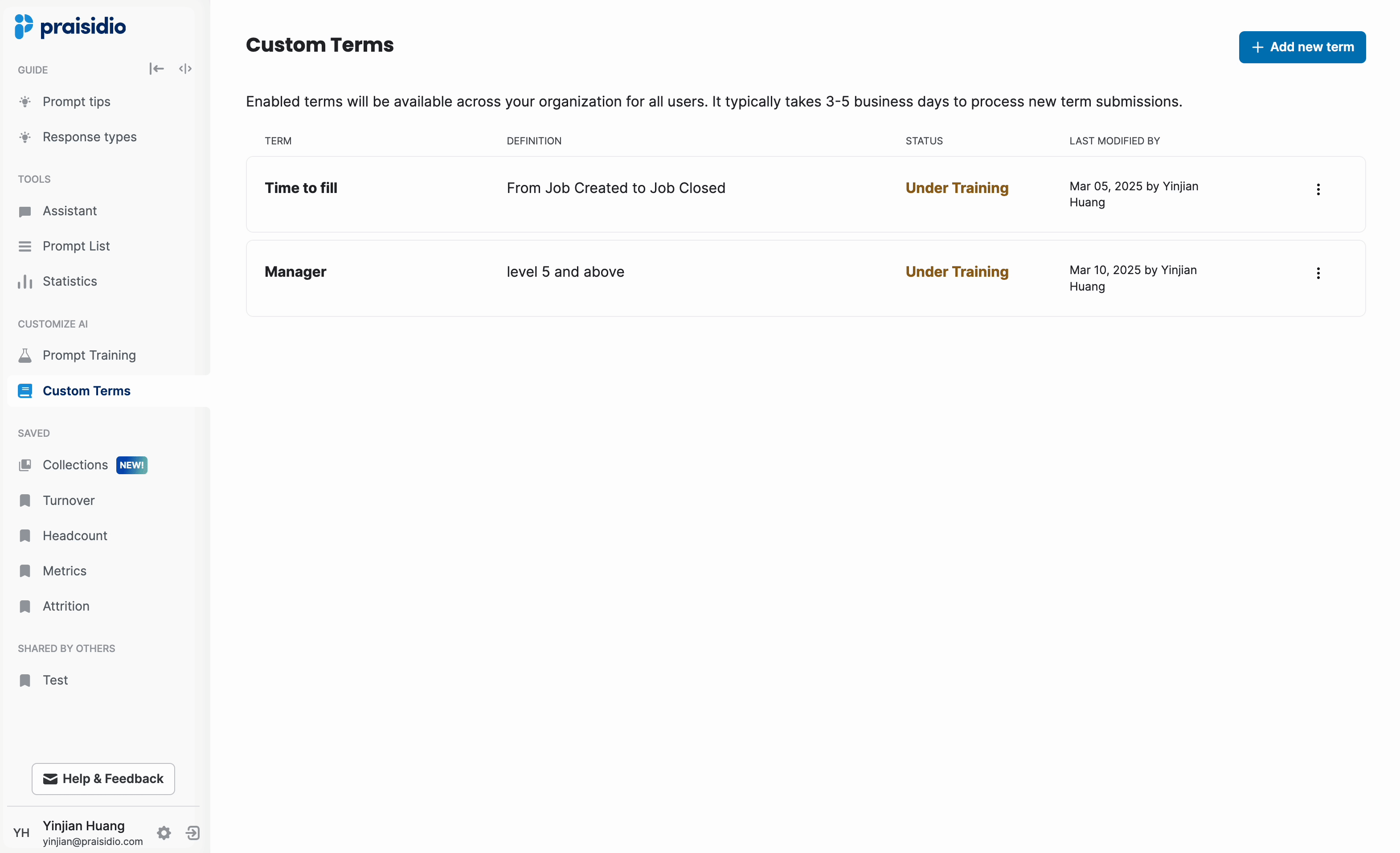
Solution: Progressive explanation exposure
Instead of cluttering responses, I introduced progressive disclosure to provide details only when needed. Not all responses raised doubts, and users often only wanted to verify specific answers, so making explanations on-demand reduced unnecessary cognitive load. Generating longer explanations also increased response time, so this approach balanced detail and efficiency. To support seamless implementation, I provided a detailed template for the model engineer, ensuring consistency in how explanations were structured and surfaced.
Impact
• Increased ongoing activation from 10% → 30%, as users gained confidence in AI calculations and continued asking questions.
• Reduced time spent explaining AI-generated answers by 80%, since users could self-verify results.